
Pruning Deep Neural Networks via a Combination of the Marchenko-Pastur Distribution and Regularization
Published in Arxiv, 2025
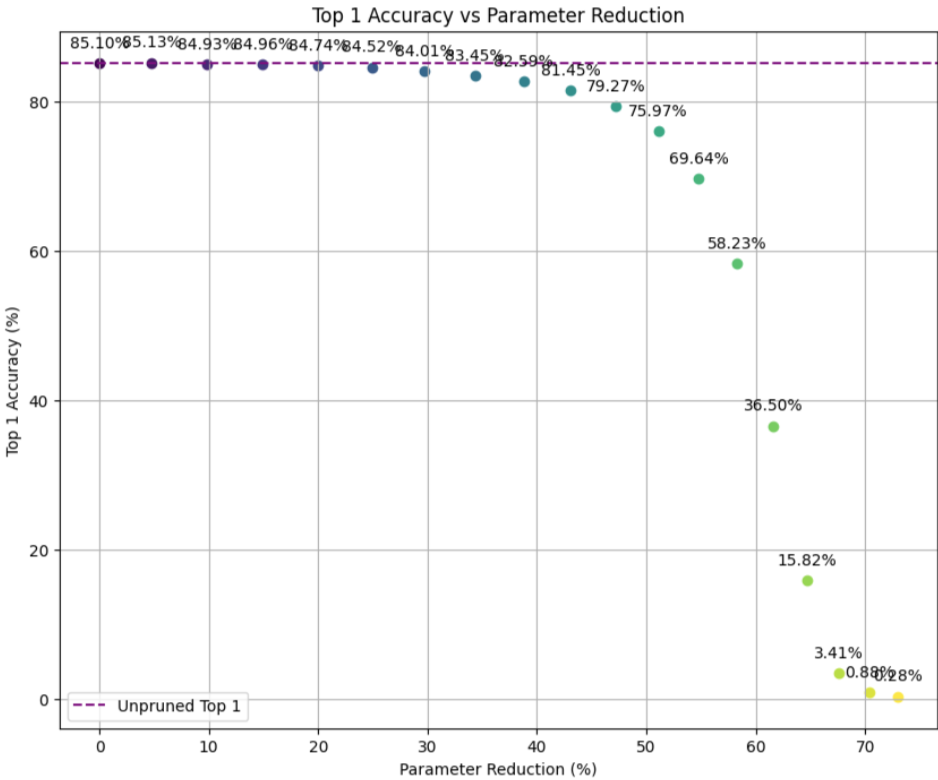
Performance of our RMT-based pruning method on ViT-Base-16 model trained on ImageNet. The plot shows the relationship between model sparsity and Top-1 accuracy, demonstrating our method’s ability to maintain high performance even with substantial parameter reduction.
Abstract
Deep neural networks (DNNs) have brought significant advancements in various applications in recent years, such as image recognition, speech recognition, and natural language processing. In particular, Vision Transformers (ViTs) have emerged as a powerful class of models in the field of deep learning for image classification. In this work, we propose a novel Random Matrix Theory (RMT)-based method for pruning pre-trained DNNs, based on the sparsification of weights and singular vectors, and apply it to ViTs. RMT provides a robust framework to analyze the statistical properties of large matrices, which has been shown to be crucial for understanding and optimizing the performance of DNNs. We demonstrate that our RMT-based pruning can be used to reduce the number of parameters of ViT models (trained on ImageNet) by 30-50\% with less than 1\% loss in accuracy. To our knowledge, this represents the state-of-the-art in pruning for these ViT models. Furthermore, we provide a rigorous mathematical underpinning of the above numerical studies, namely we proved a theorem for fully connected DNNs, and other more general DNN structures, describing how the randomness in the weight matrices of a DNN decreases as the weights approach a local or global minimum (during training). We verify this theorem through numerical experiments on fully connected DNNs, providing empirical support for our theoretical findings. Moreover, we prove a theorem that describes how DNN loss decreases as we remove randomness in the weight layers, and show a monotone dependence of the decrease in loss with the amount of randomness that we remove. Our results also provide significant RMT-based insights into the role of regularization during training and pruning.